![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Tru64 UNIX operating system fully supports the following Korean codesets by including locales and codeset conversion support:
It also provides codeset conversion support for the following codesets:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The ASCII, KSC5636-1993 (KS Roman), and KSC5601-1992 character sets (excluding the additional Hangul characters defined an Annex 3 of the standard) are combined to form the DEC Korean codeset, which is denoted as deckorean.
DEC Korean uses a two-byte data representation for symbols and ideographic characters defined in KSC5601-1992. To differentiate KSC5601-1992 characters from ASCII, the most significant bit (MSB) of both bytes of KSC5601 characters is always set on.

The first byte of a two-byte code determines its row number, while the second determines its column number. The following formula illustrates the code of a two-byte KSC5601 character in relation to its row and column numbers:
1st byte = A0 + row number
2nd byte = A0 + column number
For example, if a character is at the first column of the 36th row, its encoded value is calculated as follows:
1st byte = A0 (hex) + 36 = C4 (hex)
2nd byte = A0 (hex) + 01 = A1 (hex)
In this case, the character code is C4A1.
Figure 2-2 illustrates the division of a two-byte code space and the position of KSC5601-1992 characters.
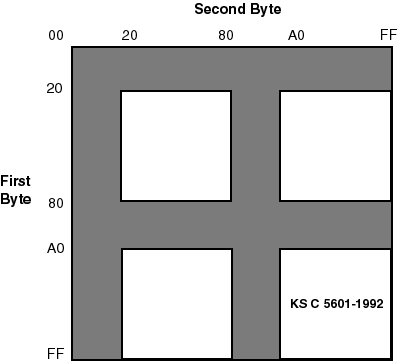
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Extended UNIX Code (EUC) is an encoding methodology that allows concurrent use of up to four code sets in a data stream. Korean EUC uses that method to combine ASCII and KSC5601. Korean EUC is currently identical to DEC Korean, and is denoted as eucKR.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Microsoft has developed Unified Hangul Code (UHC) also known as "Extended Wansung" for its Windows 95 operating system. It is an optional character set of Win95K. Microsoft calls this Code Page 949.
Unified Hangul provides full compatibility with KSC5601-1992 EUC encoding, but adds additional encoding ranges to hold additional precombined Hangul characters (more precisely, the 8,822 that are needed to fully support the Johab character set). The following table provides the encoding ranges for UHC encoding:
Two-Byte Standard Characters |
Encoding Ranges |
|---|---|
First byte range |
0x81-0xFE |
Second byte ranges |
0x41-0x5A, 0x61-0x7A |
One-Byte Characters |
Encoding Range |
|---|---|
ASCII |
0x21-0x7E |
Note that the encoding ranges 0xA1A1 through 0xFEFE are identical in terms of character-to-code allocation with KSC5601-1992 in EUC Encoding.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The ISO-2022-KR codeset consists of the following character sets:
It is assumed that the starting code of the text is ASCII. ASCII and Korean characters are distinguished by use of the shift function. For example, the code SO indicates that the upcoming bytes are Korean characters as defined in KSC5601. To return to ASCII the SI code is used.
Therefore, the escape sequence, shift function and character set used in a text are as follows:
Control Sequence |
Character Set |
|---|---|
SO |
KSC5601-1992 |
SI |
ASCII |
ESC $ ) C |
Appears once in the beginning of a line before any appearance of SO characters |
Currently, the ISO-2022-KR codeset can be used in codeset conversion.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The UCS character set is a standard character encoding for the universal character set (UCS) specified in the Unicode and ISO/IEC 10646 standards. There are two encoding schemes for UCS. An implementation that parses in 16-bit units (2 octet units) is known as UTF-16. This is the canonical Unicode encoding in wide use on personal computers. An implementation that parses in 32-bit units (4 octet units) is know as UCS-4. This is the canonical ISO/IEC 10646 encoding that is in use on systems that can support larger data size units.
On Tru64 UNIX, UTF-16 and UCS-4 encoding can be used for codeset conversion. In addition, UCS-4 is used as an internal process code for some locales. For information about codeset conversion, see Section 2.7. For information about locales, see Chapter 3.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Unicode and ISO/IEC 10646 standards define transformation formats for the universal character set. For the most part, the following UCS transformation formats (UTFs) exist to transform UCS values into sequences of bytes to be handled by various byte-oriented protocols:
The the operating system supports UTF-8 and UTF-16. UTF-8 can be used in codeset conversion and in locales. For information about codeset conversion, see Section 2.7. For information about locale variants, see Chapter 3.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The iconv utility provided by Tru64 UNIX converts the encoding of characters in one codeset to another and writes the results to standard output. Korean codeset converters provided are shown in Table 2-1.
DEC Korean |
Korean EUC |
ISO-2022-KR |
KSC5601/cp949 |
UTF-16 |
UCS-4 |
UTF-8 |
|
|---|---|---|---|---|---|---|---|
DEC Korean |
- |
Y |
N |
Y |
Y |
Y |
Y |
Korean EUC |
Y |
- |
Y |
N |
N |
N |
N |
ISO-2022-KR |
N |
Y |
- |
Y |
N |
N |
N |
KSC5601/cp949 |
Y |
N |
Y |
- |
Y |
Y |
Y |
UTF-16 |
Y |
N |
N |
Y |
- |
Y |
Y |
UCS-4 |
Y |
N |
N |
Y |
Y |
- |
Y |
UTF-8 |
Y |
N |
N |
Y |
Y |
Y |
- |
For example, you can enter the following command to convert a DEC Korean file to a Korean UTF-8 file:
% iconv -f deckorean -t UTF-8 <file>
Table 2-2 shows the codesets and the strings you use as parameters to the iconv utility.
Codeset |
Parameter String |
|---|---|
DEC Korean |
deckorean |
Korean EUC |
eucKR |
ISO-2022-KR |
ISO-2022-KR, iso-2022-kr |
Unified Hangul |
KSC5601,cp949 |
Universal Codeset |
UTF-16, UCS-4 |
Universal Transfer Format |
UTF-8 |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The operating system provides a mechanism by which you configure your system to run applications with peripherals, such as terminals and printers, supporting different codesets. You can specify the codesets for the applications, terminals, and printers independently as shown in Table 2-3. The operating sytem software automatically does the necessary codeset conversion.
Application Code |
Terminal Code |
Printer Code |
|---|---|---|
DEC Korean |
DEC Korean |
DEC Korean |
Korean EUC |
Korean EUC |
Korean EUC |
UTF-8 |
UTF-8 |
|
Note
The dxterm terminal emulator utility does not support UTF-8 as a terminal code. Use the dtterm terminal emulator utility when UTF-8 is required for a terminal code.
For details about setting up terminal code and printer code, see Using International Software.
![]()
![]()
![]()
![]()
![]()
![]()
![]()