[
English
| French
]
Documentation
This document is intended to describe the major aspects of GNUnet,
from the user interface down to the deepest internals. The document is
organized such that it will start with general issues, then go to
using the existing implementation, configuration, system design,
protocols and finally ideas for future work. So most readers will want
to start at the beginning and give up somewhere in the middle.
Like most documentation, it will probably never really be finished.
You are of course welcome to help bring it closer to that stage!
If you like code, there is
Doxygen generated documentation (HTML) available that you may want
to look at. The HTML converted man pages
are now also available.
Table of Contents

- Copyright and Contributions
- Design Goals and Philosophy
- Installation
- User Interface
- Concepts
- The GNUnet configuration file
- System Design
- GNUnet Protocol I: node-to-node
- GNUnet Protocol II: client-to-node
- Code Modules
- Future Work
Some fairly special topics that are mostly relevant for very advanced
users and developers have their own dedicated page:
- Transport services
- Content encoding
- Namespaces and directories
Copyright and Contributions
GNUnet is part of the GNU
project. All code contributions must thus be put under the GNU Public License
(GPL). All documentation should be put under FSF approved licenses
(say fdl). GNU
standards and the GNU
philosophy should be adhered to.
Design Goals and Philosophy
The goal of the GNUnet
project is to become the ultimate system for free information
exchange in a world hostile toward uncontrolled communication. We
value free speech above state secrets, law-enforcement or intellectual
property. GNUnet is supposed to be an anarchistic network, where the
only limitation for peers is that they must contribute enough back
to the network such that their resource consumption does not have a
significant impact on other users.
GNUnet's primary design goals are to protect the privacy of its users
and to guard itself against attacks or abuse. GNUnet does not have any
mechanisms to control, track or censor users. Instead, the GNUnet
protocols aim to make it as hard as possible to find out what is
happening on the network or to disrupt operations.
We call GNUnet a network because we want to support any operation that
is typically performed on a network. While the first versions only
support anonymous file-sharing, other applications such as mail, news or
distributed computation will hopefully follow in the future. Running
additional applications over the link-to-link encrypted peer-to-peer
infrastructure increases the anonymity of the peers as the set of users
and the amount of encrypted traffic grows. Increasing privacy is the
primary reason why GNUnet is developed to become a peer-to-peer framework.
A rudimentary chat client has been implemented as reference code for how
to implement other applications on top of the GNUnet peer-to-peer
infrastructure.
For GNUnet, efficiency is not paramount. If there is a more secure and still
practical approach, we would choose to take the more secure
alternative. telnet is more efficient than ssh, yet
it is obsolete. Hardware gets faster, and code can be
optimized. Fixing security issues as an afterthought is much harder.
While security is paramount, practicability is still a requirement.
The most secure system is always the one that nobody can use. Since
individual security requirements may vary, the only good solution here
is to allow individuals to trade-off security and efficiency. The
primary challenge in allowing this is to ensure that the economic
incentives work properly. In particular, this means that it must be
impossible for a user to gain security at the expense of other
users. Many designs (e.g. anonymity via broadcast, see P5) fail to give users an incentive to choose
a less secure but more efficient mode of operation. GNUnet should
avoid whereever possible to rely on protocols that will only work if
the participants are benevolent. While some designs have had
widespread success while relying on parties to observe a protocol that
may be sub-optimal for the individuals (e.g. TCP Nagle), a protocol
that ensures that individual goals never conflict with the goals of
the group is always preferable.
Anonymity can always only be achieved with large numbers of participants.
Thus it is important that we make GNUnet easy to use and well-documented.
Installation
First, in addition to the GNUnet sources you should
download the latest version of
libextractor
and install that library. This can typically be done
using
# ./configure --prefix=$HOME
# make
# make install
Then make sure that $HOME/lib is in your
library path, either by setting LD_LIBRARY_PATH
or by adding it to /etc/ld.so.conf if you are
root (in this case, substitute $HOME with
/usr/local). Then compile and install GNUnet
using:
# ./configure --prefix=$HOME --with-extractor=$HOME
# make
# make install
Finally, copy the default GNUnet configuration file into
your home-directory:
# mkdir $HOME/.gnunet
# cp contrib/gnunet.conf $HOME/.gnunet/gnunet.conf
If you are root, you may want
to copy the configuration to /etc/skel/
instead of $HOME. Every GNUnet user must
have an individual configuration file installed under
$HOME/.gnunet/gnunet.conf!
Finally, start the server using
# gnunetd
If you want to automatically start the service each time
your machine boots contrib/initgnunet contains
an example script to start the server as user
gnunet with a configuation in
/var/lib/GNUnet/gnunet.conf. You may want to
use contrib/gnunet.conf.root as a tempalte
for that configuration.
User Interface
 The only useful application that is currently available for GNUnet is
anonymous file-sharing. The GUI interface is described here. For shell-gurus, five shell commands provide
the interface:
The only useful application that is currently available for GNUnet is
anonymous file-sharing. The GUI interface is described here. For shell-gurus, five shell commands provide
the interface:
gnunet-insert
The command gnunet-insert can be used to add content to the
network. The basic format of the command is
# gnunet-insert [-n] -f FILENAME "Description" KEYWORDS*
The option -f is used to specify the name of the file that should be
inserted. The description (which must be in quotes) is displayed to
other users when they select which files to download. KEYWORDS is a
space-separated list of keywords that users can use to query for the
file. You can supply any number of keywords, and each of the keywords
will be sufficient to locate and retrieve the file.
The
description and the keywords are optional if you have libextactor
installed and libextractor is able to infer keywords and a description
from the file.
By default, GNUnet indexes a file instead of copying it. This is much
more efficient, but requries the file to stay unaltered at the
location where it was when it was indexed. If you intend to move,
delete or alter a file, consider using the option -n which
will force GNUnet to make a copy of the file in the database. Since it
is much less efficient, this is strongly discouraged for large files.
When GNUnet indexes a file (default), GNUnet does not
create an additional encrypted copy of the file but just computes a
summary (or index) of the file. That summary is approximately two
percent of the size of the original file and is stored in GNUnet's database. Whenever a request for a part of an
indexed file reaches GNUnet, this part is encrypted on-demand and send
out. There is no need for an additional encrypted copy of the file to
stay anywhere on the drive. This is very different from other systems,
such as Freenet where each
file that is put online must be in Freenet's database in encrypted
format, doubling the space requirements if the user wants to preseve a
directly accessible copy in plaintext.
Thus indexing should be used for all files where the user will keep
using this file (at the location given to gnunet-insert) and does not
want to retrieve it back from GNUnet each time.
The option -n may be used if the user fears that the file
might be found on his drive (assuming the computer comes under the
control of an adversary). When used with the -n flag, the
user has a much better chance of denying knowledge of the existence of
the file, even if it is still (encrypted) on the drive and the
adversary is able to crack the encryption (e.g. by guessing the
keyword).
Multiple files can be inserted in one run with the
gnunet-insert-multi command. If you want to remove a file
that you have indexed from the local peer, use the tool
gnunet-delete to un-index the file.
Before you can insert, index, share, search or download files from
GNUnet you must start the GNUnet server, gnunetd.
gnunetd has the following common options:
# gnunetd -c CONFIGFILE -u USER
CONFIGFILE specifies the location of the configuration file. If you
start gnunetd as root (which is not
required), you can use the -u option such that GNUnet runs as a
different user. If a group of the same name exists, GNUnet will also
change to that group.
The command gnunet-search can be used to search for content
on GNUnet. The format is
# gnunet-search [-t TIMEOUT] KEYWORD [AND KEYWORD]*
The -t option specifies that the query should timeout after
approximately TIMEOUT seconds. A value of zero is interpreted as no
timeout. If multiple words are passed as keywords and are
not separated by an AND, gnunet-search will
concatenate them to one bigger keyword. Thus,
# gnunet-search Das Kapital
and
# gnunet-search "Das Kapital"
are identical. You can use AND to separate keywords. In that case,
gnunet-search will only display results that match all the
keywords. gnunet-search cannot do multiple independent
queries ("OR"); you must use multiple processes for
that. Mind that each GNUnet-server (gnunetd) has a built-in
limit on the number of clients (like gnunet-search or
gnunet-download) that can connect simultaneously (you can
change this value in src/include/config.h).
Search results are printed by gnunet-search like this:
gnunet-download -o "COPYING" -- 77DBE6F971D66F641B2262DDCE78CA8FB6815E60\
E34BFD7843D4C8469EFC3DAD260F1F71783E2A87 466DC92 17992
=> The GNU Public License <= (mimetype: unknown)
The first line is the command you would have to enter to download the
file. The argument passed to -o is the suggested filename
(you may change it to whatever you like). The -- is followed
by key for decrypting the file, the query for searching the file, a
checksum (in hexadecimal) finally the size of the file in bytes. The
second line contains the description of the file; here this is
"The GNU Public License" and the mime-type (see the options
for gnunet-insert on how to change these).
In order to download a file, you need the three values
returned by gnunet-search. You can then use
the tool gnunet-download to obtain the file:
# gnunet-download -f FILENAME -- HASH1 HASH2 CRC SIZE
FILENAME specifies the name of the file where GNUnet
is supposed to write the result. Existing files are
overwritten. If you want to download the GPL from the previous
example, you do the following:
# gnunet-download -o "COPYING" -- 77DBE6F971D66F641B2262DDCE78CA8FB6815E60\
E34BFD7843D4C8469EFC3DAD260F1F71783E2A87 466DC92 17992
If you ever have to abort a download, you can continue it
at any time by re-issuing gnunet-download with the
same filename. In that case, GNUnet will not
download blocks again that are already present. GNUnet's
file-encoding mechanism will ensure file integrity, even if
the existing file was not downloaded from GNUnet in the
first place. You may want to use the -V switch (must
be added before the --) to turn on verbose reporting.
In this case, gnunet-download will print the current
number of bytes downloaded whenever new data was received.
The option -c CONFIGFILE can be passed to each of the
commands to override the default location of the
configuration file. The option -v shows the current
version number. Use -h to get a short description of
the options.
gnunet-stats
gnunet-stats is a little tool that displays
statistics. The numbers are for the current gnunetd
process only. The output looks similar to this,
depending on which modules you have been loading and
what your node has been doing so far:
# bin/gnunet-stats
Uptime (seconds) : 115
# kb of storage used : 402821
# kb of storage remaining : 645755
% of allowed network load : 42
% of allowed cpu load : 0
# bytes of noise received : 200
# bytes received from clients : 16
# times outgoing msg sent (bandwidth ok) : 6
# times outgoing msg dropped (bandwidth stressed) : 0
# times incoming msg accepted (cpu ok) : 10
# times incoming msg dropped (cpu overloaded) : 0
# ping messages sent : 1
# ping messages received : 2
# pong messages sent : 2
# pong messages received : 1
# sessionkeys received : 1
# valid sessionkeys received : 0
# sessionkeys sent : 1
# connections shutdown : 0
# currently connected nodes : 1
# bytes noise sent : 2656
# encrypted bytes sent : 7260
# bytes decrypted : 10164
# bytes received via tcp : 22744
# bytes sent via tcp : 9076
# bytes received via udp : 15794
# bytes sent via udp : 8016
# HELO messages received from http server : 29
# HELO messages received overall : 7
# valid HELO messages received : 2
# HELO messages forwarded from other peers : 0
# HELO messages originated : 0
# Bloomfilter (content_bloomfilter) hits : 0
# Bloomfilter (content_bloomfilter) misses : 34
# Bloomfilter (content_bloomfilter) adds : 0
# Bloomfilter (content_bloomfilter) dels : 0
# Bloomfilter (keyword_bloomfilter) hits : 0
# Bloomfilter (keyword_bloomfilter) misses : 196
# indexed files : 4
# size of indexed files : 1544183
# lookup (3HASH, search results) : 0
# lookup (CHK, inserted or migrated content) : 1
# lookup (ONDEMAND, indexed content) : 0
# times storage full : 0
# kb content pushed out as padding : 0
# kb downloaded by clients : 0
# kb ok content in : 0
# kb dupe content in : 0
# kb orphan or pushed content in : 1
# p2p queries received : 45
# p2p CHK content received (kb) : 1
# p2p search results received (kb) : 0
# client queries received : 0
# client CHK content inserted (kb) : 0
# client 3HASH search results inserted (kb) : 0
# client file index requests received : 0
# file index requests received : 0
# super query index requests received : 0
The number of connected hosts is the nummber of hosts
that the local node is directly connected to (1 hop). The total
number of hosts in the network must be larger or
equal to this number. Note that TIMESTAMP
messages are not send by the current implementation and thus
the counter is pretty much always zero. Also the server-client
protocol is asymmetric. For example, it is currently impossible that the
client receives a STATREQ
message.
While the numbers shown above are from an actual node,
they may not be representative. GNUnet-developers are working
on reducing the amount of noise needed and on improving the
ratio between queries send and responses routed.
gnunet-gtk
gnunet-gtk is the GTK+ interface for GNUnet.
It can currently only be used to search for and
download files from the network. gnunet-gtk
can also be used to insert files into the network. If you
want to insert lots of files, you're probably better of
using gnunet-insert or even
gnunet-insert-multi.
After gnunet-gtk was started, you should see the
following:
 Enter the query into the input line at the bottom and click on search.
A new window will open. In that window, search results obtained
from the network will be listed once they arrive.
gnunet-gtk will keep searching for the query until
you close that window. No duplicate results will be displayed.
Enter the query into the input line at the bottom and click on search.
A new window will open. In that window, search results obtained
from the network will be listed once they arrive.
gnunet-gtk will keep searching for the query until
you close that window. No duplicate results will be displayed.
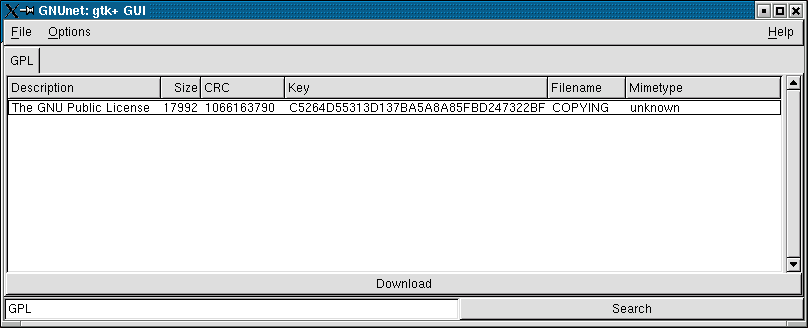 You can enter additional queries or select a file to download
from the list. The size of the file is displayed in bytes. Mind that
the description was supplied by the user inserting the file and
may not be accurate. After you click on the download button,
the entry selected will be removed from the results list and a
dialog will prompt you for the filename that you want to give to
the file.
If you choose an existing file, that file will be overwritten without
any warnings. If the existing file contains the same data (even in
parts) as the file that you are trying to download, those parts will
not be downloaded again. You can use this feature to continue downloads
that were incomplete. After you gave a filename, click on ok. The
dialog will disappear and gnunet-gtk will start the download.
A small window with a progress bar will tell you what percent
has already been downloaded:
You can enter additional queries or select a file to download
from the list. The size of the file is displayed in bytes. Mind that
the description was supplied by the user inserting the file and
may not be accurate. After you click on the download button,
the entry selected will be removed from the results list and a
dialog will prompt you for the filename that you want to give to
the file.
If you choose an existing file, that file will be overwritten without
any warnings. If the existing file contains the same data (even in
parts) as the file that you are trying to download, those parts will
not be downloaded again. You can use this feature to continue downloads
that were incomplete. After you gave a filename, click on ok. The
dialog will disappear and gnunet-gtk will start the download.
A small window with a progress bar will tell you what percent
has already been downloaded:
 If you close this window before the download is complete,
gnunet-gtk will abort the download. This will
leave the parts of the file that were already downloaded
on the drive. Be advised that the download usually starts
very slowly, then speeds up, and eventually declines a bit again
at the end. This is perfectly normal. Go get a coffee while
doing the download. GNUnet uses a lot more time (but not
much more bandwidth) because it delays processing to make
traffic analysis hard. Even downloading a file from your local
harddrive (that you inserted yourself) can take a couple of
minutes! The good news is that the delays will become smaller
whenever the traffic on GNUnet increases.
If you close this window before the download is complete,
gnunet-gtk will abort the download. This will
leave the parts of the file that were already downloaded
on the drive. Be advised that the download usually starts
very slowly, then speeds up, and eventually declines a bit again
at the end. This is perfectly normal. Go get a coffee while
doing the download. GNUnet uses a lot more time (but not
much more bandwidth) because it delays processing to make
traffic analysis hard. Even downloading a file from your local
harddrive (that you inserted yourself) can take a couple of
minutes! The good news is that the delays will become smaller
whenever the traffic on GNUnet increases.

In order to insert a file, use the File menu. A
dialog will pop up and prompt you to choose the file to
insert:
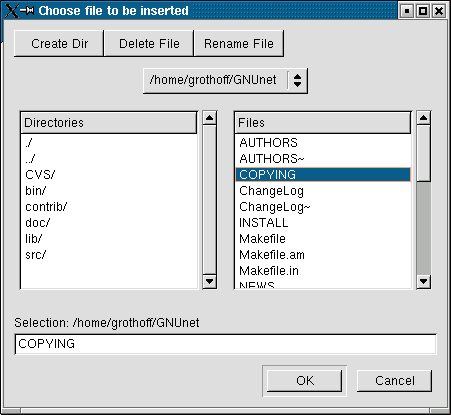
Select the file and press ok. Next you will have
to provide a description and keywords and choose if
you want to index or insert the file
(choose index if the file will not be moved or deleted
to safe space):


Finally, press ok and watch GNUnet making the file available:

You can even do these things in parallel:
Concepts
In this section, the fundamental concepts of GNUnet are
explained. Most of them are also described in one our research papers.
Anonymity
Anonymity in GNUnet is achieved even when facing powerful
adversaries. Providing anonymity for users is the central goal
behind the whole system, thus, many other design decisions follow in
the footsteps of this requirement.
Contrary to other designs, we do not believe that users achieve
anonymity just because their requests are obfuscated by a couple of
indirections. This is not sufficient if the adversary uses traffic
analysis. In our model, the adversary is very powerful. We assume that
the adversary can see all the traffic on the Internet. And while we
assume that the adversary can not break our encryption,
we assume that
the adversary has many participating nodes in the network and that it
can thus see many of the node-to-node interactions since it controls
some of the nodes.
GNUnet is build on the idea that users can be anonymous if they can
hide their actions in the traffic created by other users. Hiding
actions in the traffic of other users requires participating in the
traffic, bringing back the traditional technique of using indirection
and source rewriting. Source rewriting is required to gain anonymity
since otherwise an adversary could tell if a message originated from a
host by looking at the source address. If all packets look like they
originate from a node, the adversary can not tell which ones originate
from that node and which ones were routed. Note that in this midset,
any node can decide to break the source-rewriting paradigm without
violating the protocol, as this only reduces the amount of traffic
that a node can hide its own traffic in.
If we want to hide our actions in the traffic of other nodes, we must
make our traffic indistinguishable from the traffic that we route for
others. As our queries must have us as the receiver of the reply
(otherwise they would be useless), we must put ourselves as the
receiver of replies that actually go to other hosts; in other words,
we must indirect replies. Unlike other systems, with GNUnet we do not
have to indirect the replies if we don't think we need more traffic to
hide our own actions. This increases the efficiency of the network as
we can indirect less under higher load.
Deniability
Even if the user that downloads data and the server that provides data
are anonymous, the intermediaries may still be targets. In particular,
if the intermediaries can find out which queries or which content they
are processing, a strong adversary could try to force them to censor
certain materials.
With GNUnet, this problem does not arise because queries and content
are transmitted in an encrypted format such that intermediaries cannot
tell what the query is for or what the content is about. Mind that
this is not the same encryption as the link-encryption between the
nodes. In GNUnet, the traffic between the nodes is encrypted on each
link to provide authentication and confidentiality (see below). But
the queries and the content that the nodes transport over these links
are also encrypted. GNUnet has encryption on the network layer (link
encryption, confidentiality, authentication) and again on the
application layer (provided by gnunet-insert,
gnunet-download, gnunet-search and
gnunet-gtk).
Authentication
As GNUnet requires accounting (see next section), we need to
authenticate all communications. This is achieved using an RSA-based
exchange of a secret session-key. That session-key is then used to
encrypt the communication between the two hosts using Blowfish. As
only the two participating hosts know the session-key, this
authenticates each packet without requiring signatures. Furthermore,
encrypted traffic makes any kind of traffic analysis much harder.
In GNUnet, the identity of a host is the hash of its public key. For
that reason, man-in-the-middle attacks will not break the
authentication or accounting goals. Essentially, for GNUnet, the IP
of the host does not matter. As the public key is the only thing that
truly matters, faking an IP, a port or any other property of the
underlying transport protocol is irrelevant.
GNUnet uses a special type of message to bind public keys to their
current address. For the UDP and TCP transport layers, an address is
an IP and a port. In the future, other transport mechanisms (HTTP,
SMTP, etc.) could be used and may deploy various other forms of
addresses. Note that any node can have multiple addresses for the
various transport mechanisms.
Cryptography
GNUnet uses 2048 bit RSA keys for the
session key exchange and for signing messages by peers.
Most researchers in cryptography consider 2048 bit RSA keys
as very secure and practically unbreakable for a very long
time unless extraordinary advances in cryptography are made.
For the encryption of the files and the symmetric peer-to-peer
communication GNUnet uses 128 bit keys with blowfish. Fresh
session keys are negotiated for every new connection. Again,
there is no published technique to break this cipher in any
realistic amount of time. Note that GNUnet does not use RSA
to encrypt files or ordinary individual peer-to-peer
messages (no sane protocol uses public key cryptography for
the bulk of the messages since public key
encryption is extremely expensive compared to symmetric
ciphers; GNUnet follows the well-established practice to use
public key cryptography to exchange an initial symmetric key
that is then used for the rest of the messages).
Accounting
Most distributed P2P networks suffer from a lack of defenses or
precautions against attacks in the form of freeloading. While the
intentions of an attacker and a freeloader are different, their effect
on the network is the same; they both render it useless. Most simple
attacks on networks such as Gnutella involve flooding the network with
traffic, particularly with queries that are, in the worst case,
multiplied by the network.
In order to ensure that freeloaders or attackers have a minimal impact
on the network, GNUnet must between distinguish good (contributing)
nodes from malicious (freeloading) nodes. In GNUnet, every node keeps
track of the behavior of every other node it has been in contact
with. GNUnet's economic model ensures that nodes that are not
currently considered to have a surplus in contributions will not be
served if the network load is high.
Confidentiality
Adversaries outside of GNUnet are not supposed to know what kind of
action a node is performing, and even participating nodes can never
tell what an action is about (which data is transferred or what the
query is for) nor who initiated the action. This helps GNUnet to be
hard to compromise even with attacks that use traffic analysis and
malicious nodes in combination. Of course, the fact that a node is
performing a request will still be revealed if all other nodes in the
network collaborate aganist it. In this situation, the only recourse
the node has is that the other nodes may not be able to determine the
contents of the action. As far as we know, this determination is only
possible if the adversary can guess the contents or break
cryptographic primitives.
The GNUnet configuration file
The file gnunet.conf contains the configuration for the
GNUnet server and the applications. All GNUnet programs expect this
file to reside in $HOME/.gnunet/gnunet.conf. The option
-c can be used if the file is located elsewhere.
In gnunet.conf the location of all the other files described
in this section can be configured. We discuss the function of these
files in their sections. The good news is, typically you don't have to
worry about configuration at all. There are a few exceptions,
though. You may want to configure a few things in
gnunet.conf. The most important options are described
below. If you are on dialup, look at HELOEXPIRES and probably INTERFACES. If you are behind a NAT
box, look at IP. If you are a frontier
host that is accessible from a trusted LAN and connected to the
Internet, have a look at TRUSTED,
BLACKLIST and HELOEXCHANGE.
The configuration of the SMTP transport layer is described
here.
NETWORK: HOST
With this option, you can specify to which host the gnunet-clients
should connect by default. You can override the choice you make here
with the -H option. The default, localhost should be
fine. Note that this option has no effect on gnunetd since it
can always only open a port on the machine running gnunetd.
NETWORK: PORT
With this option, you can specify to which TCP port the gnunet-clients
should connect. It is also the choice of the port for
gnunetd. While you can restrict access to this port using the
NETWORK: TRUSTED option, you may
also want to firewall this port. A different port must be used for the
TCP and UDP peer-to-peer transport mechanism. The default value is
2087.
NETWORK: INTERFACE
Use this option to specify which interface GNUnet should use to try to
determine your IP. Alternatively, you can use the IP option.
NETWORK: IP
This option allows you to specify the advertised IP. If you do not
specify anything, GNUnet will attempt to detect the IP. You really
need this option if you are behind a NAT box. In that case, you have
to specify the IP of the NAT box here (you can use a hostname, DNS is
supported). For NAT boxes with changing IP, you may want to use Dynamic DNS.
NETWORK: HELOEXCHANGE
If you set this option to NO your node will not forward HELO
messages that advertise other nodes. This option only makes sense if
your node bridges two networks that both contain GNUnet nodes but that
can not contact each other directly. The default value is
YES. Stick to the default if you are unsure.
NETWORK: TRUSTED
With this option you can specfiy which addresses are trusted enough to
connect to gnunetd via TCP as clients. The default is only the local
host. If you are on a trusted LAN, you may want to specify the LAN
network and netmask. You must use IPs, DNS lookup is not supported.
LOAD: INTERFACES
Under this option you specify which interfaces GNUnet is going to
monitor to determine the load. If you have ethernet, the default is
eth0. If you have a modem, try ppp0. In general, the
command ifconfig (may not be in your path if you are logged
in as a normal user, try /sbin/ifconfig) will show you the
active devices.
LOAD: BASICLIMITING
Use basic bandwidth limitation? YES or NO. The basic method
notes only gnunet traffic and can be used to specify simple
maximum bandwidth usage of gnunet. Choose the basic method if
you don't want other network traffic to interfere with gnunets
operation, but still wish to constrain gnunet's bandwidth usage,
or if you can't reliably measure the maximum capabilities of your
connection. The basic method might also be good when the used
interface can transmit data to/from local network very fast
compared to internet traffic (a condition that makes the advanced
method unreliable).
The advanced bandwidth limitation measures total traffic
over the chosen interface (including gnunet traffic),
and allows gnunetd to participate if the total traffic is
low enough.
LOAD: MAXNETBPSUPTOTAL
If you use basic bandwidth limitation, this option specifies
the maximum gnunet can use for its internal traffic. When
using advanced limiting, use this option to specify your maximum
upload speed (how many bytes per second your node can send). In
that case, do not specify how much you want GNUnet to use,
but use the maximum theoretically available. If you do not
know your bandwidth, stick with the default of 50.000 bytes.
LOAD: MAXNETBPSDOWNTOTAL
Same as MAXNETBPSUPTOTAL,
but for download speeds. Note that while GNUnet can not control
exactly how much data other nodes are sending to your machine (this is
only implicitly controlled if GNUnet drops connections because the
bandwidth is used up), the upload limit is enforced strictly. If we
are above our boundaries for the download limits, GNUnet will drop all
traffic until we are back inside the limits. Note that if you disable
BASICLIMITING, GNUnet will sense that other traffic is going on and
only use the specified amount of bandwidth if you are not using it
otherwise.
LOAD: MAXCPULOAD
Up to which CPU load will GNUnet process packets from other nodes. If
the average CPU load goes over this value (like for the network, this
includes other applications), GNUnet will start dropping packets and
reduce the load. For example, if you are running an application that
takes up all of your CPU power, GNUnet will pretty much not serve any
other nodes (the node is considered busy). Only if the load
is under the value specified here, GNUnet will serve other nodes. The
default is 50, which should keep your hosts responsive enough while
being more than sufficient for GNUnet on any modern machine.
UDP: PORT
Which port should the UDP transport layer use? If no value
is specified, GNUnet will try to find a port in /etc/services.
If you specify 0, this means that you do not want to open UDP for
receiving messages (but, if you load the transport module, you can
still send UDP traffic). The default port is 2086 as assigned to
GNUnet by IANA. Since other peers
will try to connect to this port, you should configure your firewall
to let all traffic through. UDP is a stateless protocol, thus just
allowing related traffic in a stateful firewall will not
be sufficient.
UDP: BLACKLIST
If your node receives advertisements for nodes on virtual private
networks, it should not even attempt to connect to those networks.
You can use this option to specify a list of networks that are
forbidden. gnunetd will then never attempt to communicate with these
addresses. You will get an error if your own IP address is listed
here.
UDP: MTU
This option specifies the maximum transfer unit, the maximum number of
bytes that GNUnet will put in a UDP packet. This does not include the
IP or UDP headers. Do not use more than your OS (and firewall) can
support. Typcially, your want to avoid fragmentation and should choose
network-MTU minus 28. You can determine your MTU using the
ifconfig command. For ethernet, the network MTU should be 1500 octets,
resulting in 1472 octets for the GNUnet MTU,
which is also the default. Do not use values smaller than 1200.
TCP: PORT
Which port should the TCP transport layer use? If no value is
specified, GNUnet will try to find a port in /etc/services.
If you specify 0, this means that you do not want to open TCP for
receiving messages (but, if you load the transport module, you can
still initiate bi-directional TCP connections). Setting the TCP port
to 0 is a common configuration for machines behind NAT boxes (these
peers can then still initiate connections but other nodes will not
attempt to connect). The default port is 2086 as assigned to GNUnet by
IANA. Since other peers will try to
connect to this port, you should configure your firewall to let all
traffic through. Make sure that the port number you select here does
not conflict with the client TCP port.
TCP: BLACKLIST
If your node receives advertisements for nodes on virtual private
networks, it should not even attempt to connect to those networks.
You can use this option to specify a list of networks that are
forbidden. gnunetd will then never attempt to communicate with these
addresses. You will get an error if your own IP address is listed
here.
TCP: MTU
This option specifies the maximum transfer unit, the maximum number of
bytes that GNUnet will put in a TCP packet. This does not include the
IP or TCP headers. Typcially, your want to avoid fragmentation and
should choose network-MTU minus 40. For ethernet, this would result
in 1460 octets, which is also the default. Do not use less than 1200.
TCP: MAXTCPCONNECTS
The maximum number of concurrent TCP connections allowed. Note that
the current implementation ignores this value. The default is 64.
AFS: DISKQUOTA
Use this option to specify how much space GNUnet is allowed to use on
the drive. This does not include indexed files. The value is
specified in MB, the default is 1024. Note that whenever you change
this value, GNUnet may have to reorganize the database, which can take
quite some time on the next start (obviously depending on the previous
size of the database).
Large amounts of storage space may also have some impact on memory
use, a typical value is around 250 kb memory per gigabyte of storage
space. Note that indexing files (instead of inserting, indexing is
the default, insertion can be enforced with the -n switch) is
much cheaper; the files will cause less memory usage, use less space
in the database and the operation will be faster.
AFS: ANONYMITY-RECEIVE
With this option you can specify the required degree of receiver
anonymity. If set to zero, GNUnet will try to download the file as
fast as possible without any additional slowdown by the anonymity code
due to a lack of traffic. Note that you will still have a fairly high
degree of anonymity due to link-to-link encryption, small uniform
messages, pseudo-random routing and random delays. Still, your
anonymity will depend on the current network load if the adversary is
powerful enough to monitor most of your traffic. The download is still
unlikely to be terribly fast since the sender may have requested
sender-anonymity and since in addition to that, GNUnet will still do
the anonymous routing.
This option can be used to limit requests further than that. In
particular, you can require GNUnet to receive certain amounts of
traffic from other peers before sending your queries. This way, you
can gain very high levels of anonymity - at the expense of much more
traffic and much higher latency. So set it only if you really believe
you need it.
The definition of ANONYMITY-RECEIVE is the following:
- If the value v is smaller than 1000, it means that if GNUnet routes n bytes
of messages from foreign peers, it may originate n/v bytes of queries
in the same time-period. The time-period is twice the average delay
that GNUnet deferrs forwarded queries.
- If the value v is larger or equal to 1000, it means that if GNUnet
routes n bytes of QUERIES from at least (v % 1000)
peers, it may originate n/v/1000 bytes of queries
in the same time-period.
The default is 0 and this should be fine for most users. Also notice
that if you choose high values, especially above 1000, you may end up
having no throughput at all, especially if many of your fellow
GNUnet-peers do the same.
AFS: ANONYMITY-SEND
You can also request a certain degree of anonymity for the files and
blocks that you are sharing. In this case, only a certain faction of
the traffic that you are routing will be allowed to be replies that
originate from your machine. Again, 0 means unlimited.
The semantics of ANONYMITY-SEND are equivalent to
the semantics of ANONYMITY-RECEIVE.
The default is 0 and this should be fine for most users.
AFS: ACTIVEMIGRATION
Setting this option to YES allows gnunetd to migrate copy to
the local machine. Setting this option to YES is highly
recommended for efficiency. Its also the default. If you set this
value to YES, GNUnet will store content on
your machine that you can not decrypt. While this may protect you
from liability if the judge is sane, it may not (IANAL). If you put
illegal content on your machine yourself, setting this option to YES
will probably increase your chances to get away with it since you can
plausibly deny that you inserted the content. Note that in either case,
your anonymity would have to be broken first (which may be possible
depending on the size of the GNUnet network and the strength of the
adversary).
AFS: INDIRECTIONTABLESIZE
Indirection table size, minimum and default is 8192 entries.
Enlarge if you start to overflow often and have memory available.
If the average query lives for say 1 minute (10 hops), and you have
a 56k connection (= 420 kb/minute, or approximately 8000
queries/minute) the maximum reasonable routing table size would
thus be 8192 entries. Every entry takes about 56 bytes.
The larger the value is that you pick here, the greater your
anonymity can become. It also can improve your download speed.
AFS: SEARCHTIMEOUT
After how many seconds should gnunet-search give up searching? The
default is 300 seconds.
AFS: EXTRACTORS
Which additional extractors should gnunet-insert use for keyword
extraction. The default set of extractors from your local
libextractor installation is always used. Typically, an extractor
for splitting keywords at word boundaries is added here.
AFS: DATABASETYPE
Which database type should be used for content? Valid types are
"gdbm", "tdb", "bdb" , "mysql"
and "directory". Specified type must have been available at
compile time. "directory" is available on all systems. If
the type is changed, you must stop gnunetd and run
gnunet-convert to convert the database.
Here are some performance numbers for the databases from Eric Haumant
(for a 100 MB file with random content):
| Database |
Upload Speed |
Download Speed |
Space used |
| mysql |
400 kb/s |
300 kb/s |
113 MB |
| gdbm |
500 kb/s |
400 kb/s |
148 MB |
| tdb |
27 kb/s |
12 kb/s |
118 MB |
| bdb |
340 kb/s |
260 kb/s |
435 MB |
| directory |
100 kb/s |
300 kb/s |
450 MB |
Note that these numbers may be slightly different between different
machines and different versions of GNUnet. Nevertheless, they should
help you pick the right database for you (the choice is between work
required to do the setup vs. performance).
GNUNETD: HELOEXPIRES
This option specifies how long (in minutes) your node will claim to be
reachable under the current IP. If you have a permanent IP, a couple
of days can be a reasonable value. If you are on dialup, you may want
to choose only an hour. The default is 1440 (1 day). The largest
acceptable value is 14400 (10 days).
GNUNETD: MAXCONNECT
The total number of nodes with which the current node will maintain a
session-key for. Must be a power of 2, Set rather high as it doesn't
cost much; this is NOT Gnutella. Note that the value is the number of
connections that the local node will try to maintain. Often the actual
number of connections will be lower, but even a higher connection
count is possible if other peers connect to the local node after it
has reached this value.
GNUNETD: LOGLEVEL
Loglevel, how much should be logged? You can use NOTHING, FATAL,
ERROR, FAILURE, WARNING, MESSAGE INFO, DEBUG, CRON or EVERYTHING
(which log more and more messages in this order). Default is
WARNING. You can override this option at the commandline with the
-L switch.
GNUNETD: LOGFILE
If gnunetd is not started with the -d option, it
writes logging messages into this file (with -d all messages
are written to the console). Read this mail
if you are using logrotate.
GNUNETD: TIMESTAMPS
Should the logfile contain timestamps?
GNUNETD: PIDFILE
In which file should gnunetd write the process-id of the server? If
you run gnunetd as root, you may want to choose
/var/run/gnunetd.pid. It's not the default since gnunetd may not have
write rights at that location.
GNUNETD: HOSTS
In this directory GNUnet stores the key and last known Internet
address of each known GNUnet node. Each file is about 550 bytes long
(different transport protocols may have different address sizes). A list of GNUnet hosts can be obtained
from the GNUnet webpage. On startup, GNUnet downloads a list of
initial hosts from
http://www.ovmj.org/GNUnet/download/hostlist. This list is
generated using
# cat ~/.gnunet/data/hosts/* > hostlist
Alternative hostlist servers can be used by modifying
gnunet.conf.
Once connected, GNUnet hosts exchange information about other hosts
automatically. Thus except for the initial connection, there should be
no pressing need to obtain a new list (except if a node was offline
for a long time and the old list aged so much that it became
useless). If hosts cannot be reached and the time that the key has
been signed to be valid by the sender has expired, GNUnet deletes
their identities from data/hosts/. Note that the trust
information is kept "forever".
GNUNETD: HOSTLISTURL
Whenever gnunetd is started, it downloads a list of initial nodes to
connect to via http. The URL to use is specified here.
GNUNETD: APPLICATIONS
Which applications should gnunetd support? Specify the name of the
dynamic shared object (DSO) that implements the service in the gnunetd
core here. Currently, only the "afs_protocol" is available.
The default is "afs_protocol".
GNUNETD: TRANSPORTS
Which transport mechanisms are available? Use space-separated list of
the modules, e.g. "udp smtp tcp". For SMTP, please read the
SMTP documentation for details.
GNUNET-INSERT: CONTENT-PRIORITY
What is the initial priority of content that is locally inserted?
Default is 65535 which is very high (every day, content
ages by 2 points; thus inserting content at 65535 will make it
age to unimportant in about 100 years).
The contrib/ directory contains a
template that should be self-explanatory.
System Design
This section is intented to be an introduction to programmers that
want to extend the framework. GNUnet has a layered design. The basic
goal for the layering is this:
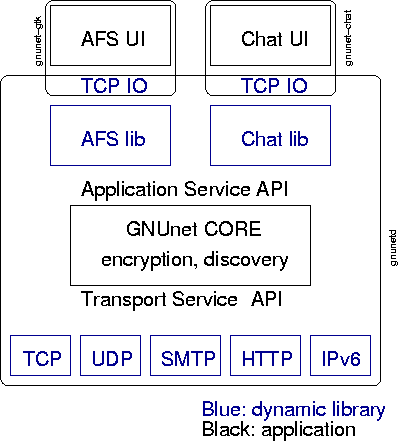
| Layer |
Example |
code in |
| User Interface(s) |
gnunet-gtk |
apps/afs/tools/, apps/afs/gtkui/ |
| Application Logic |
anonymous file sharing, statistics |
apps/afs/encoding/, apps/afs/protocol/, apps/afs/database/ |
| Core |
gnunetd |
server/ |
| Transport |
udp, tcp |
transports/ |
The util/ directory contains utility methods that could even
be useful without GNUnet (io, cron, semaphores, etc.). util/
is thus used throughout the system. util/ contains also
cryptographic primitives and the configuration system.
The
test/ directory contains (always too few) testcases. The
historical/ directory contains old code that is not used
anymore but maybe useful in the future. The include/
directory contains all the include files in a directory structure that
matches the tree for the code.
In GNUnet, the server gnunetd is responsible for accounting,
routing and link-to-link encryption. The core relies on
implementations of the TransportAPI for the
actual transport of packets. The transport layer has, like the
internet protocol (IP), best-effort semantics. There is no guarantee
that a message will be delivered.
Services (like anonymous
file-sharing) are build on top of GNUnet. Services use the CoreAPIForApplication
to access the GNUnet core. Services are responsible for adding
reliability (through retransmission) to the networking layer. The
service is also responsible for avoiding congestion (see TCP). While
the core will enforce bandwidth limitations set by the user, services
should implement better strategies.
In order to ease the implementation of a service, GNUnet splits
services in two parts. The first part resides in the process space of
gnunetd and is always available to the GNUnet core. The core
will notify this lowest layer of the service of messages that have
arrived for the service. This layer of the service is responsible for
all node-to-node interactions (for AFS, this layer provides routing,
content lookup and handles QUERY/CONTENT messages). The second part of
every service is an application which is invoked by the user. The idea
is that the user starts a sepearate program (like gnunet-search,
gnunet-download or gnunet-gtk) which provides a user interface to the
service. This user interface uses a trusted (local) TCP connection to
talk to the in-process part of the service.
The GNUnet core
provides an easy way for services to register
for certain types of messages from the application. The tcpio implementation provides
functions to send and receive messages via TCP. Note that the TCP
connection between the application and gnunetd is presumed to
be totally secure (i.e. via loopback). You can specify the list of
trusted IP addresses (i.e. the LAN) that are allowed to connect as
clients to GNUnetd.
We now describe how you can write your own applications, interfaces
and transport mechanisms for the GNUnet peer-to-peer framework.
How do I write a new application service for GNUnet?
The directory src/applications/template/
contains the minimal piece of code that you will need to start. You may also want to look
at src/applications/chat/ for a simple example.
Most simple applications will consist of two pieces of code:
-
The first is a dynamic library that plugs into the GNUnet
core. This library must provide a single function which is invoked by the core
when gnunetd starts. This function registers a couple of
callbacks with the GNUnet core in order to handle certain
peer-to-peer messages. Every peer-to-peer message is bounded in size
(1300 octets) and must be bound to the appropriate application
module using a number typically defined in src/include/util/ports.h. The
number must be globally unique. The core module will be called
whenever a peer-to-peer message matching a registered port number is
received. The core module can send messages to other nodes using the
CoreAPIForApplication. Typically, the module will also make use
of GNUnet's client-server implementation tcpserver to
communicate with a user interface. Like with peer-to-peer messages,
the service can register for client-server messages.
-
The second piece of code is a user interface application. Some implementations
may even use a set of user interface applications (for example, the anonymous
file sharing has gnunet-search, gnunet-insert, gnunet-download
and a GUI that provides the combined functionality, gnunet-gtk). It depends
on the specifics of the application if it uses dynamic libraries or not. The application
must communicate with the service module that is loaded into the GNUnet core. While any
IPC mechanism should theoretically work, the preferred way that is used by all existing
GNUnet applications is tcpio, a simple TCP connection
that communicates with the tcpserver.
The simplest way for a user interface to connect to the GNUnet core via TCP is to use
the helper methods defined in the common
library, which defines methods for
parsing the command line options
and getting a client socket that is connected to
gnunetd.
How do I write a new transport mechanism for GNUnet?
The best way to start implementing a new transport mechanism is to
start with existing code that is semantically as close to the new
mechanism as possible. The most important criteria is if the
connection is stateful and bidirectional (TCP) or stateless and
unidirectional (UDP, SMTP). Since reliability and delays are handled
by the applications, these criteria are irrelevant for choosing an
implementation to evolve from.
Every new transport mechanism must define an identification number in
ports. Note that this number is used
purely internally in GNUnet and does not have to correspond to the underlying
protocol in any way (though of course it can help users to understand which
transports 25, 17 or 6 are if these numbers magically match well-known
ports or IP protocol numbers).
For details on the transport API see our transport
paper.
How do I write a new user interface for GNUnet?
Typically, you will not want to write a user interface for the gnunetd
peer-to-peer deamon but for some specific GNUnet application. The first
step is typically to factor the application code into a library that
implements the core functionality (like talking to gnunetd via tcpio)
and a simple shell application. For anonymous file-sharing, the
primary libraries for the user interface are in
src/applications/encoding/.
The next step is to examine the small shell-tools to get an idea how
the application specific libraries work and to evolve the shell-tools
into a user interface. You may also decide to just invoke the shell-tools as
separate processes that do the real work, though this is much less
efficient and less powerful (thus this is not the recommended approach).
Threading and Synchronization
GNUnet is inherently multi-threaded. Thus writing applications for GNUnet requires
taking synchronization issues into account. GNUnet provides a minimal set of
threading abstractions in the semaphore
module, including semaphores, mutexes, recursive mutexes and thread creation.
When writing code for GNUnet, the following basic rules must be followed:
- The core may call registered callback handlers at any time, and also
concurrently. The application modules are responsible for synchronizing
access to their internal state properly. In practice, client code
will use MUTEX_CREATE in initializers and then guard access to mutable
global shared state using MUTEX_LOCK and MUTEX_UNLOCK.
- In order to avoid deadlocks, code that was called via callback from the
core may not invoke methods on the core while holding locks of the
application. The rationale behind this rule is that the core may
have a thread A that holds an internal lock L and calls a callback on the
service. If simultaneously another thread B holds a lock S of the service
and calls back on the core, this may result in a deadlock if that callback
blocks trying to aquire lock L and thread A blocks trying to aquire lock
S. If thread A does not hold any internal locks when calling on the core,
this situation can be safely avoided.
Programming with this paradigm is not very difficult. Still, it often
requires a simple trick if the callback to the core requires an argument
that is typically kept in the shared global state. The trick is, to copy
the shared global state into a local buffer while holding the lock, then
releasing the lock and finally doing the callback on the core. An example
for this behavior can be found in the
querymanager code.
- Core threads should never be blocked indefinitely. The core has
a limited number of processing threads. If clients (service modules in the
core or applications connecting via TCP) block these threads, the core will
stop working. Disk-IO is typically not problematic (though excessive
synchronous random IO operations may degrade performance significantly),
and synchronization with other threads is also no problem (as long as they
do not deadlock). Encryption operations are also not the problem. The only
problem in practice are blocking socket operations. Blocking
socket operations occur pretty much only apply to TCP sockets.
The TCP transport layer avoids blocking operations using select calls and
IO buffers. If a message can not be buffered (buffer full) and sending would block,
the TCP transport layer discards the message (or: why we like unreliable operational
semantics). Client-server TCP connections are more problematic. First of all, the
client-server connection has reliable semantics. Thus the gnunetd tcpio
code blocks on writes to the client. Similarly, the client blocks when sending messages
to gnunetd. Since the client-server TCP connection is supposed to use a fast
(loopback, LAN) connection and since gnunetd uses a thread per client connection,
blocking on this connection is acceptable. The problem with blocking here is that
it leaves the possibility of an inter-process deadlock.
The deadlock can occur if the TCP thread that receives and processes messages from the
client blocks on a write to the client (TCP buffer queue full) and thus gnunetd
no longer reads from the TCP pipe. If the client blocks on a write to gnunetd and
thus no longer reads from its end of the TCP connection, both processes block forever.
This problem is typically hard to diagnose since it involves two processes and
may only occur after the TCP buffers of the operating system are full. A typical
symptom is that netstat -tn shows two local TCP connections with very full
receive and send buffers that do not change.
The solution to the problem is that every client (not peer, remember that clients are
trusted and can thus be expected to follow the protocol correctly) must always be in
a state where it has a thread that can receive and process messages from gnunetd. That
thread should never block, neither by doing a direct write to gnunetd nor by aquireing
a lock that could be hold by another thread while that thread writes to gnunetd. A
typical solution to this problem is to use one thread that processes replies and another
thread that generates requests. The RequestManager
code is an example for this code. It uses the cron thread
to send requests to gnunetd and a separate processing thread to process replies.
GNUnet Protocol I: node-to-node
The GNUnet node-to-node (peer-to-peer) procotol currently defines eleven different
messages:
The most basic sequence is that a host sends a HELO
to any other host to notify it of its existance on the network.
The recipient of the HELO sends back a PING to confirm
that the host is actually reachable. The receiver of the PING always sends
back a PONG to confirm receit.
Later, either of the hosts sends the other host a SKEY
message to initiate a connection. The receiver acknowledges this with a
PING, just this time using the encrypted channel that
was established with the session key. Again, the PING is answered with
a PONG, which is also again encrypted. If no PING is received,
the initiator can send another SKEY. If no PONG is received,
the responder can send another PING. This sequence is pretty much equivalent
to the initial three-way handshake in TCP.
The following diagram illustrates a possible sequence of messages:

Nodes then exchange service messages like the
QUERY, CHK
and 3HASH
messages. TIMESTAMP and SEQUENCE
numbers can be used to prevent a malicious adversary to
replay packets. NOISE must be used to make packets look
uniform in size. The MTU is determined by the transport layer and
advertised in the HELO message.
HANGUP can be used by any of the nodes
to drop the connection. A connection that is inactive for
a long time (about 15 minutes) is also considered dropped.
The HANGUP is neither acknowledged nor required.
A packet exchanged between GNUnet hosts can contain
any number of messages (only limited by the MTU of the transport layer).
The transport layer implementation is responsible for encapsulating the
message appropriately. In addition to the message itself, the transport
mechanism must communicate:
- The sender identity (hash of public key)
- If the message is in plaintext or encrypted
- The CRC of the (plaintext) message
- The size of the message
Depending on the implementation of the transport mechanism, not all of
these must be transmitted for each message, for example, a stateful
transport such as TCP may only transmit the sender identity once and
use special messages to switch between plaintext and encrypted messages.
The current UDP implementation encapsulates messages in this
format:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| size of the packet (NBO) |
is the message encrypted (YES=1, NO=0)
(NBO) |
| crc (NBO) |
| sender identity |
| sender identity |
| sender identity |
| sender identity |
| sender identity |
| Messages ... |
The size of the UDP packets is by default 1472 octets, the advertised
MTU to the GNUnet core is 1444 octets. If your network MTU is
smaller than 1500 octets (ethernet), you may want to specify
a different MTU in the configuration.
The encryption (blowfish) of the noise-padded body
is done by the GNUnet core, the transport implementation only needs
to transmit the information listed above. For received packets, the
transport is not responsible for checking the CRC.
The GNUnet core will decrypt the message (if applicable) and
compute the CRC over the body of the packet (all
messages) in plaintext. If the CRC check fails the core
will discard the message silently.
Each of the messages in the body has the
form
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| message size |
request Type |
followed by message size octets for the message.
GNUnet clients are required to skip unknown request types.
The message-size field is the size of the message in
octets excluding the message size field itself (but not
the request type field).
HELO
A HELO packet is used to propagate information about participating
nodes throughout GNUnet. Each GNUnet node is identified by its
public key K. Throughout GNUnet, the public key of a node is often
abbreviated by just the hash of K, short H(K).
The HELO packet is the way nodes propagate public keys of other
nodes. Furthermore, the identity of the node is bound
to an address. How an address is specified depends on the underlying
transport mechanism that is used. For example, the UDP service uses
the IP and the UDP port. An SMTP transport implementation may choose
to use an E-mail address.
GNUnet nodes can have multipl addresses and change addresses at
any time, e.g. if the IP is dynamically assigned,
like in DHCP or on dialup. The HELO message
is used to notify other hosts
of a changed address.
Security considerations. Malicious nodes could disrupt
GNUnet by telling nodes fake addresses. As nodes forward HELOs from
other nodes, malicious hosts could replace the address of the original
node by an invalid address. In order to prevent this, the address portion
of a HELO must be signed with the private key of the node. In order to
prevent malicious hosts from forwarding outdated addresses, the signed
portion of a HELO also contains a timestamp stating how long the HELO is
going to be valid. The administrator of each node can specify how long
the HELOs signed by that node are going to be valid; the administrator
is in the best position to judge how long the current address will be
valid.
Another security concern is where hosts send out valid, signed HELO
messages with IPs of non-participating machines. The goal of this
attack could either be to flood the non-participating hosts with
traffic (trick GNUnet into performing an attack) or to make it hard
for the receiver to find a valid GNUnet host in the ocean of addresses
that it learned from the HELOs.
GNUnet defends against this type of attack by sending a PING to the
acclaimed host and only believes the HELO of a PONG is received. Thus
the malicious host sending fake HELOs will fail to trick GNUnet into
repeatedly trying to connect to the non-participating host.
Receivers of HELOs must verify the signature and check that the HELO
has not expired. Nodes should delete HELOs that have expired for a
long time. HELOs that expired just a short time ago may belong to
nodes that may re-appear. GNUnet nodes may still keep trying to
connect to these nodes, but their HELOs should no longer be propagated.
HELOs can be send to hosts without an established encrypted connection
(in plaintext). This is necessary because HELOs and SKEYs
are needed to form the encrypted channel in the first place. Once an encrypted
channel was formed, nodes can exchange HELOs via that channel.
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| size (NBO) |
0 (type) (NBO) |
|
RSA signature (256 octets) |
| Public Key,
length of N + E + 2 (256+2+2 = 260) (NBO) |
Public Key, length of N (256) (NBO) |
| Public Key, N (256 octets) |
| Public Key, E |
padding (must be 0) |
|
sender Identity |
| sender Identity |
| sender Identity |
| sender Identity |
| sender Identity |
| expiration time |
| sender address size (octets)(NBO) |
transport protocol number (NBO) |
| MTU (NBO) |
| sender address (sender address size bytes) |
For the UDP and TCP transport mechanisms, the sender address has this
format:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| IP (NBO) |
| sender port(NBO) |
reserved (must be 0) (NBO) |
The sender address size is thus 8 octets for UDP and TCP.
SKEY
Sessionkeys are 128 bit keys for blowfish, a symmetric cipher that
is used for all communication between GNUnet nodes except HELOs
and SKEYs themselves (for those, RSA with 2048 bit keys is used).
A session between two GNUnet nodes is the existance of a common,
active sessionkey between the two nodes. Even if the underlying
protocol may be connectionless, the notion of a session is
still meaningful for GNUnet.
A session key exchange may be initiated by either node. SKEYS are
always encrypted with the public key of the receiving node. They
are usually not send through an encrypted channel (if nodes
that already have an SKEY pair decide to exchange a fresh sessionkey,
that key may be send via the encrypted channel; even in that case,
the key must also be encrypted with the public key of the receiving
node).
The sender of a session key not only encrypts the key with the
public key of the receiver but also signs it (together with an
creation time) with its own private key. The sender must remember
the sessionkey and can start using it after receiving an acknowledgement
(in the form of a PING) from the receiver.
The format of an
SKEY message is the following:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 520 (size) (NBO) |
1 (type) (NBO) |
| creation time (not expiration!) (NBO) |
| RSA Encrypted data (256 octets) |
| Signature (256 bytes) |
Notice that while SKEY is not aligned, there should be
nothing following an SKEY Message in a packet since afterwards
the new sessionkey is used.
PING
PINGs are used to test if a node receives messages correctly.
PINGs are exchanged in encrypted and in plaintext. The receit
of a PING must be answered by a PONG with identical body
(the receiver just changes the type). The challenge number in
a PING is a random number that is used to make it impractical
for an adversary to guess the contents of the PING and thus
hard to fake a PONG response.
The identity stored in the PING is the identity of the receiver.
If that identity does not match, the PING must be silently discarded.
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 24 (size) (NBO) |
2 (type) (NBO) |
| receiver identity |
| receiver identity |
| receiver identity |
| receiver identity |
| receiver identity |
| challenge |
PONG
PONGs are responses to PINGs. If the node is not aware of
a corresponding PING (or if the challenge is wrong),
the PONG is silently dropped. Otherwise the
appropriate action corresponding to the PING is triggered.
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 24 (size) (NBO) |
3 (type) (NBO) |
| receiver identity |
| receiver identity |
| receiver identity |
| receiver identity |
| receiver identity |
| challenge |
TIMESTAMP
TIMESTAMPs can be used by GNUnet nodes to make replay
attacks harder. If a message contains a TIMESTAMP, the
receiver checks that the current time is before the
given time. If that is not the case, the rest of the
message is discarded silently.
Senders are advised to use rather timespans because
GNUnet nodes may not be perfectly synchronized in
time. The current implementation honors timestamps
but does not generate them itself.
SEQUENCE numbes are used to guard against replay
attacks instead. For UDP with a low chance of reordered
messages, this is appropriate. Other transport protocols
(like E-Mail) may work better with TIMESTAMPs.
The format of a timestamp message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 8 (size) (NBO) |
4 (type) (NBO) |
| expiration time (seconds since 1970) (NBO) |
Timestamps numbers may only be used in encrypted traffic (HELOs
and SKEYS have another form of timestamps integrated into
the signed part of the message).
SEQUENCE
The format of a sequence number message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 8 (size) (NBO) |
5 (type) (NBO) |
| sequence number (NBO) |
A node may keep track of the last sequence number that
another node was using. If it receives a packet with a lower
sequence number, that packet must be discarded. Whenever a
sessionkey exchange takes place, this last sequence number
must be reset to 0. A sequence number of 0 is invalid.
Sequence numbers are unsigned 32 bit integers. Sequence
numbers may only be used in encrypted traffic.
NOISE
Noise is used to fool adversaries that perform
traffic analysis. A node receiving noise should
just silently ignore it. Nodes may append noise
to packets that are short to make all packets
look more uniform in size. Noise should only be
used in encrypted traffic. The format for noise is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| size in octets, ≥ 4 (NBO) |
6 (type) (NBO) |
| noise |
The number of bytes of noise should be a multiple of 4
to preserve alignment, except at the end of a packet where
perfectly identical packet sizes are more important.
The noise in the packet should be (pseudo) random.
HANGUP
The format of the HANGUP message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 24 (size) (NBO) |
7 (type) (NBO) |
| sender identity |
| sender identity |
| sender identity |
| sender identity |
| sender identity |
When a HANGUP message is received, the node must stop using
the current sessionkey (assuming the sender that is given in the
message matches the sender of the message).
If further communication is desired,
a new sessionkey may be exchanged.
The anonymous file-sharing service (AFS) defines three messages:
QUERY
GNUnet's anonymous file sharing uses two basic types of
queries, queries that search unknown content and queries
for downloading. The search queries contain the triple-hash
of the keyword and the response is a 3HASH
message.
The download queries contain the hash of the encrypted block,
the response is a CHK message. In their
pure form, both types of queries can not be distinguished,
only after a reply was found, the responder can tell which
form of query was encountered.
The download-query has a variant, the multi-query with
super-hash. In this form, a single query message contains
multiple hash-code requesting multiple blocks of the same
file. A multi-query message does not have a different
protocol number but can be identified by looking at the
size-field of the query message, which is 32+n*20 bytes.
If n is greater than 1, the query must be a multi-query.
A multi-query groups multiple hash codes from the same
IBlock. The first hash code of a multi-query is called
the 'super' hash. It is the hash of the concatenation of
all hash-codes of the IBlock. It is followed by up to
25 hash codes from that IBlock. The 'super' hash can be
used to speed-up the lookup process since it can be
treated as a summary of the other hash codes that follow.
Note that even if the IBlock had 25 hash codes, not all
must be included in the multi-query. Thus the super-hash
can typically not be obtained from the following queries.
Multi-queries do not exist for queries that search for
content.
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 32+20*n (size) (NBO) |
16 (type) (NBO) |
| priority (NBO) |
| time-to-live (NBO) |
| return to (NBO) |
| return to |
| return to |
| return to |
| return to |
| query[n] |
| query[n] |
| query[n] |
| query[n] |
| query[n] |
Note that the query can be the triple-hash for a search or
the hash of the encrypted block for a download. The receiver
can not tell the difference until a reply is found. Depending
on if the query matches a triple-hash or a CHK query, the
receiver sends back a CHK
or a 3HASH reply.
3HASH
A 3HASH content message is a reply of a GNUnet node to a
QUERY that is a search. The difference
between a search and a download is that there can be multiple
results to a search, whereas there can only be one, unique
result for a download. The 3HASH reply
contains the encrypted data EKD and the
double-hash H2 = H(K). The encrypted data
is always 1k in size. The receiver computes the double-hash
and verifies that it matches the triple-hash of the QUERY
that was originally sent. If that is the case, the receiver
trusts that the content matches the query (the sender was able
to invert the hash) and forwards it to the next destination.
3HASH messages
may only be exchanged via an encrypted channel
(to make traffic analysis harder). See also the
GNUnet encoding paper and
the encoding page for the way
data is transmitted in GNUnet.
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 1048 (size) (NBO) |
17 (type) (NBO) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| 1024 octets of encrypted content |
CHK
A CHK content message is a reply of a GNUnet node to a
QUERY that was used to download a
specific file.
It contains the encrypted data EH(D)(D). The hash
of the encrypted data must match the original query,
H(EH(D)(D)). The encrypted data
is always 1k in size. The plaintext was padded with zeros
if necessary. The receiver computes the hash of the content
and verifies that it matches the query of the QUERY
that was originally sent. If that is the case, the receiver
forwards the reply to the next destination.
CHK messages
may only be exchanged via an encrypted channel
(to make traffic analysis harder). See also the
GNUnet encoding paper and
the encoding page for the way
data is transmitted in GNUnet.
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 1048 (size) (NBO) |
18 (type) (NBO) |
| 1024 octets of encrypted content |
Additional applications may define more messages. The assigned numbers
should be noted in ports.h.
Experimental messages should use high numbers (> 60000).
GNUnet Protocol II: client-to-node
The GNUnet client-to-node procotol currently defines the following
messages:
REQUEST messages are messages from the client to
gnunetd. REPLY messages are messages from
gnunetd to the client. While gnunetd
should not send data without being asked first, the
client must silently ignore REPLY messages that were
not requested.
This protocol is used on the trusted,
reliable TCP connection between gnunetd and
the clients gnunet-insert, gnunet-search,
gnunet-download and gnunet-gtk. TCP is
stream oriented, but GNUnet breaks the stream into records.
See also tcpio.c.
Every record has the following basic format:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| size of the record (NBO) |
TCP type (NBO) |
| size bytes |
The only generic client-server (CS) message that are currently
defined are RETURN_VALUE and
GET_STATISTICS and
STATISTICS.
All other CS messages are specific to anonymous file-sharing (AFS).
CS_RETURN_VALUE
The RETURN_VALUE message is used to communicate simple (int)
return values from TCP requests.
The format of the RETURN_VALUE message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 8 (size) (NBO) |
0 (type) (NBO) |
| the return value (NBO) |
CS_GET_STATISTICS
With this message, the client can request statistics from the server.
The server always replies with a STATISTICS
message.
The format of the GET_STATISTICS message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 4 (size) (NBO) |
1 (type) (NBO) |
CS_STATISTICS
The available statistical information may change
between GNUnet versions. The
format
of this message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| (size) (NBO) |
2 (type) (NBO) |
| start time (gnunetd start) (NBO) |
| start time (gnunetd start) (NBO) |
| total counters (number of statistical values
gnunetd keeps track of) (NBO) |
| stat counters (number of statistical values
transmitted in this message) (NBO) |
| values (unsigned long long[stat counters])
(NBO) |
| descriptions (stat counters of zero-terminated
strings describing the values) |
The server sends potentially several STATISTICS messages
until the sum of stat counters in all messages equals
the total counters advertised. The last decription string
is also zero-terminated,. Thus the last char in every STATISTICS
message is 0.
CS_QUERY
The client sends a message of this form whenever it is
searching or downloading. The server is expected to perform
the search and send results back to the client. The
server can send any number of results with any delay (but
typically no results are returned after ttl seconds and
the client will re-issue the request), including none.
The format of the CS_QUERY message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 12+n*20 (size) (NBO) |
8 (type) (NBO) |
| priority (NBO) |
| time to live (ttl) (NBO) |
| query [n] |
| query [n] |
| query [n] |
| query [n] |
| query [n] |
CS_3HASH
If gnunetd finds a search result to a
QUERY, it sends
back the data encapsulated in this message. The
message contains the double hash from the
query to identify the result. The format of the message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 1048 (size) (NBO) |
9 (type) (NBO) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| data (1024 octets) |
CS_CHK
If gnunetd finds a download result to a
QUERY, it sends
back the data encapsulated in this message. The
format of the message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 1028 (size) (NBO) |
10 (type) (NBO) |
| data (1024 octets) |
CS_INSERT_CHK
Clients send this message to insert search results into the
network. The server is supposed to store the data
and share it with other nodes. Note that there are
two ways to share data, via insertion and via
indexing. Indexing only
applies to downloads and never to search results. The
importance in this message tells the server how
important it is to store this content, so that the
server can decide which content to discard if
it is running out of space.
If the insertion was successful, the server replies with
a RETURN_VALUE containing
OK, otherwise the server replies with
SYSERR.
The format of the INSERT_CHK message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 1032 (size) (NBO) |
11 (type) (NBO) |
| priority (NBO) |
| data (1024 octets) |
CS_INSERT_3HASH
Clients send this message to insert search results into the
network. The server is supposed to store the data
and share it with other nodes. The
importance in this message tells the server how
important it is to store this content, so that the
server can decide which content to discard if
it is running out of space.
If the insertion was successful, the server replies with
a RETURN_VALUE containing
OK, otherwise the server replies with
SYSERR.
The format of the INSERT_3HASH message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 1052 (size) (NBO) |
12 (type) (NBO) |
| priority (NBO) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| proof (double hash) |
| data (1024 octets) |
CS_INDEX_BLOCK
Clients send this message to insert content into the
network. The indexing message does not contain the
data but describes a way for the server to find
on-demand. The
ContentIndex struct
contains an index into the list of filenames and the
offset in the file at which the block corresponding
to the query can be found.
If the indexing was successful, the server replies with
a RETURN_VALUE containing
OK, otherwise the server replies with
SYSERR.
The format of the INDEX_BLOCK message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| (size) (NBO) |
13 (type) (NBO) |
|
ContentIndex (32 octets) |
CS_INDEX_FILE
This message is used by the client to add a file to the
list of shared files. gnunetd responds to this
request with an index into the list of files
which can be used in the CS_INDEX_BLOCK
messages. Notice that in order for on-demand sharing to work, the
inserting client and the server must have the shared file
available under the same location and thus typically run on the
same machine. The length of the filename is limited to 1023 characters.
The format of the INDEX_FILE message is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 1032 (size) (NBO) |
20 (type) (NBO) |
| length of the filename (NBO) |
0 (reserved) |
| filename, zero-terminated 1024 octets, padded with zeros |
CS_INDEX_SUPER
This message adds a hash-code to one of the bloom filters,
making the content effectively available.
The format of the INDEX_SUPER is:
| 00 | 01 | 02 | 03 |
04 | 05 | 06 | 07 |
08 | 09 | 10 | 11 |
12 | 13 | 14 | 15 |
|
| 16 | 17 | 18 | 19 |
20 | 21 | 22 | 23 |
24 | 25 | 26 | 27 |
28 | 29 | 30 | 31 |
|
| 24 (size) (NBO) |
15 (type) (NBO) |
| super hash |
| super hash |
| super hash |
| super hash |
| super hash |
Code Modules
The most important modules in GNUnet are:
There are two typical flows for data. Note that this
is the flow of the data, several threads are involved
in this.
First, a client such as
gnunet-search
or gnunet-insert
connects (via a trusted TCP connection, typically
loopback) to the tcpserver
module. The most common request is a
query
which is handed by the CORE to the AFS service and
remembered in routing. The AFS service
then produces a query which is
enqueued in the connection
module. After a while, the entire buffer is flushed
and send to the destination(s) with a little help from
the knownhosts module. This
transaction goes over the untrusted (but authenticated
and encrypted) UDP channel.
The second path comes into play after gnunetd
receives
a message on any transport mechanism. The message is
demultiplexed.
If it is a
query,
the lookup
module performs a lookup and potentially
sends a reply. If the
time-to-live
of the query is not expired, the query is remembered in the
routing module and forwarded using
the connection module.
If the message is a reply, the routing
module is considered for where to send the reply
to (local client(s) and/or other nodes).
util/configuration
The configuration
module reads the configuration using the
OpenSSL library
and provides configuration information
to the rest of GNUnet.
server/handler
This
module
verifies
the integrity of incoming node-to-node
traffic and demultiplexes
the traffic to the appropriate
handlers. The verification process decrypts encrypted
packets and performs a CRC check.
server/tcpserver
This module performs the appropriate operations for
incoming CS traffic. Since the connection
is trusted, there is only a limited amount of verification
taking place. The
tcpserver module
starts one thread
per TCP connection.
server/heloexchange
This module
is responsible for
advertising
the presence of the current node to others. It also occasionally
forwards
foreign HELOs. HELO messages that have expired are deleted
by heloexchange.
server/trustservice
The trustservice
provides access to information about how much
the local node trusts another node.
server/connection
The
connection module
stores information about to which
other nodes the local node is connected. It buffers outgoing
traffic and keeps
session information, like the sequence
number and the session key. The connection API provides
means to unicast a message to a specific node, to forward
a query to a subset of the nodes or to broadcast a message
to all other nodes.
server/keyservice
The keyservice
module manages the private key of the
local node and is used for signing, encrypting and
decrypting messages with the RSA key.
server/pingpong
The ping-pong
module is responsible to record which
ping messages were sent and to trigger actions after
a corresponding pong is received.
server/knownhosts
The knownhosts
module keeps track of the known GNUnet
nodes and provides an API to operate on that list.
This module maps node
identities (the hash of the public key of the node) to
all the information that can be obtained from the
HELO,
including the current address and the full
public key.
afs/database/
The database manager
module is responsible to check if content matching an
incoming query is available locally. The manager code is
responsible for performing the lookup and building the
response. It is also there to decide which content to store
locally (manages the resource disk space). Content migration
is also controlled by the database manager module. The
content storage is abstracted into a high-level special
purpose database abstraction, the
high backend.
There are two implementations of the high backend. The
first one uses
mysql. The
second
implementation maps the high backend
interface to a
simpler API
("low backend") that matches
the interface provided by standard trivial databases such
as gdbm,
tdb or
bdb.
afs/protocol/routing
The routing
module is responsible to keep
information
about queries that were forwarded. If the node
receives a reply, the routing module must decide whether
and if yes where to forward the reply to. Possible
destinations are clients
that are directly connected via a trusted TCP connection
or other GNUnet nodes.
The routing modul is implemented as a large hashtable.
In the case of collisions, the entry with the smallest
remaining time-to-live is discarded. Time-to-lives in
queries are bounded by the query priority to prevent malicious
peers from taking over the routing table.
Future Work
Code contributions (GPL) are generally welcome. Before writing
a larger patch, you may want to discuss the idea on
the developer mailinglist first.
Some ideas (in random order, contacts listed are people that seem
to have given the idea some thought and/or may even have some code):
- fix performance issues, in particular:
- The GNUnet protocol has no way to reply that content
is not available. Thus the current implementation of
the clients just keeps trying -- forever (unless the
user aborts). What would be better is using the size
of GNUnet (estimated via number of hosts known) to
determine by software when to better give up.
- improve documentation
- translate (documentation, user interface, messages, man-pages),
gettext
support in the code and build-system
- more powerful user-interfaces (preferences, non-gtk+).
- write more extractors for
libextractor
(contact)
- How about pseudonym based E-mail with accounting to fight
Spam? E-mail without a central server at some ISP would
also get rid of the pain with
changing the address ever again.
- port to win32 (contact)
- fix bugs
- port to OS X (contact)
- add directories and namespaces
(contact)
- implement other transport protocols (other than UDP and TCP). We
have SMTP
contact),
planned are HTTP and
IPv6 (contact).
Feel free to add smoke signals and
others to this list as you please.
And if you want to go totally crazy:
- distributed computation (sandboxing!?)
- add steganography to existing transport protocols
Footnotes
NBO - network byte order
Fields of this type are in network byte order. Before reading these
fields, they must be converted to host byte order using htons
for 2-byte values and htonl for 4-byte values. Before writing
to these fields, the value must be converted using ntohs and
ntohl respectively.
Copyright (C) 2002, 2003 Christian Grothoff.
Verbatim copying and distribution of this entire article
is permitted in any medium, provided this notice is preserved.
gnunetweb@mail.ovmj.org